Converting from C to Tram (Scanner/Parser)
This section describes how TRAM’s scanner / parser written in C was used as a basis to implement the scanner / parser in Tram.
Annotated Scanner / Parser in C
The scanner is a loop which processes input characters and terminates when EOF is read. Inside the loop a switch branches based on the current character under consideration.
Variables:
vholds the currently value being readnumandsgnare auxiliary variable used to read numberslenis an auxiliary variable used to read identifiersinandnmare file name and descriptorSis used as a stack and has been initialized in the context- register
Vis used as an auxiliary register to safeguard terms from garbage collection - register
Tcontains a list of sub-terms read so far using-s
Note: a term can be a variable, a compound term (tram(...)), or a sole function symbol f which represents a term with zero arguments. In various places where the parser expects a term, but where the scanner has seen a symbol, that symbol must be coerced to a term (by replacing f with new(f,0)). Wherever the text mentions a (possibly coerced) term, this mechanism is intended without further explanation (the code is self-evident).
| |
Note: immediately after the switch statement is the single statement:
| |
This means that the break statement results in the next character being read and the loop restarted, whereas continue restarts the loop without reading a character (i.e., when the next character has already been read).
Whitespace and comments are simply skipped.
| |
A quoted character is immediately encoded to a corresponding data value.
| |
A # can be followed by
0xfollowed by a hexadecimal value, or- a decimal value. A
0not followed byxis the beginning of a decimal value (gotois used to jump into the decimal handler). The encoding data value is computed on the fly.
| |
Meta variables contain a decimal number identifying the n-th element (in reverse order) from the list in T. This value is returned as the value just read.
| |
A Tram variable consists of *, & or an upper-case letter, followed by between zero and three letters, digits or .. Only the first four characters are significant, although variables shorter than 5 characters and variables longer than 4 characters are distinguished, so Abcd and Abcde differ, but Abcde and Abcdf are considered identical.
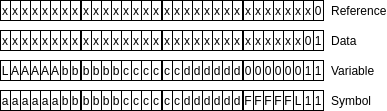
A symbol consists of $, @ or a lower-case letter, followed by between zero and four letters, digits or .. Only the first five characters are significant, although symbols shorter than 6 characters and symbols longer than 5 characters are distinguished, so abcde and abcdef differ, but abcdef and abcdeg are considered identical.
Only the first five characters are significant, so abcde and abcdef differ, but abcdef and abcdeg are considered identical.
- In a variable or symbol the L bit signifies whether the identifier is longer than the max (4 for variables, 5 for symbols)
AAAAAin a variable, orFFFFFin a symbol encode the first characteraaaaaa,bbbbbb, etcetera encode subsequent characters.
| |
So far, we have seen a scanner and not a parser. The only feature in Tram that isn’t lexical and is context free are parentheses. The scanner / parser is a push-down automaton which uses a stack (S) to hold partial results.
When a ( is encountered, a symbol must just have been seen. The current value is kept in variable v, so a term with v as outermost function symbol is pushed on the stack (new(v,0)). This term will be extended as arguments are parsed.
| |
A , means a (possibly coerced) term has just been read. That term is pushed on whatever partial term is on the stack. These pushed sub-terms therefore occur in the wrong order. We will fix this at the closing ). Note that V is cleared to avoid floating garbage, and that v is cleared because there is no current read object.
| |
Just like a ,, a ) immediately follows a (possibly coerced) term. However, that structure is in the wrong order: The last argument is on top, and the function symbols are deepest. A new object is created in which all parts occur in the right order.
| |
= occurs in a rule, but otherwise behaves as a ,.
| |
Similarly, ; terminates a rule, and behaves somewhat as a ). However, no term-structure with an outermost function symbol is created for rules, because a linked list with pairs is more efficient. That list is needed in reverse textual order, so the pair of the left- and right-hand sides is left on the stack.
| |
Finally, two situations might occur:
- A term is read (
S==nil)
The (possibly coerced) term is returned. - A TRS is read (
S!=nil)
The stack contains the pairs of left- and right-hand sides in reverse order. It is returned (Sis reset)
| |
Scanner / Parser in Tram
The main loop is implemented in the function sccc, short for ‘scan with character class’. This function implements the switch statement of the automaton and has these arguments sccc(Cc, C, S, V, Stck)
Cis the character currently being consideredCcis its character classSis the remainder of the input (string)Vis the current valueStckis the current stack
Several aspects merit explanation:
- Character class
specconcerns data-values, which start with'or# - Identifiers are scanned by
scsym; the character class of the first character (loworcapidentifies symbols and variables, respectively) - The last rule for
sccc‘catches’ all tokens which follow a term:,,;,=and). They are processed byscaffix(scan affix). firstis a function (defined in moduleLists.trm) which returns the first element of a list or string (first(lst(X,L)) = X; first(str(C,S)) = C;). The function is partial:first(eos)is a normal form. In the context of the scanner,first(eos)means: ‘we have attempted to read a character when the input was already exhausted’. That is,first(eos)has the same meaning asEOFin C. This situation is handled byscfinalize(scan finalize)
Function sccomm scans and further ignores a comment.
| |
Tram does not have a notation for character classes, so all characters are shown explicitly. The function cc determines the character class of every valid input character
| |
Note: this scanner doesn’t treat . correctly => ToDo.
scaffix
Function scaffix processes a symbol immediately following a term (i.e., ,, =, ; and )).
An = only occurs after the (possibly coerced) left-hand side of a rule. A partial rule is pushed with only the left-hand side as argument.
Otherwise, the top of the stack is a partial term, and the current value ((possibly coerced) term or variable) is added as the last argument in the top of the stack.
scaffix(equ,S,trm(F,As),Stck)
= sclini(equ,S,lst(trm(str('r',str('l',eos)),
arg(trm(F,As),eoa)),Stck));
scaffix(equ,S,F,Stck)
= sclini(equ,S,lst(trm(str('r',str('l',eos)),
arg(trm(F,eoa),eoa)),Stck));
scaffix(Cc,S,var(V),lst(T,Stck))
= sclini(Cc,S,lst(append(var(V),T),Stck));
scaffix(Cc,S,str(F,Fs),lst(T,Stck))
= sclini(Cc,S,lst(append(trm(str(F,Fs),eoa),T),Stck));
scaffix(Cc,S,trm(F,As),lst(T,Stck))
= sclini(Cc,S,lst(append(trm(F,As),T),Stck));
scaffix(Cc,S,F,lst(T,Stck))
= sclini(Cc,S,lst(append(trm(F,eoa),T),Stck));
sclini
Function sclini accepts a ) or any of (,, = and ;). In the first case (done; the last term is complete), the top-of-stack is popped and set as current value; in the second case (not yet done, the last term is incomplete and remains on the stack to be extended).
| |
scfinalize and scancollrls
Function scfinalize processes EOF. yielding either the list of pairs of left- and right-hand sides, or a term (possibly an extended symbol).
Note that whereas the C implementation needs the rules in reverse order (because thay need to be joined by the -C option), the Tram version can at this moment only process a single module. But: rules have been pushed in reverse order, so function scancollrls reverses the order of the rules.
scfinalize(first(eos),rest(eos),trm(F,As),eol) = trm(F,As);
scfinalize(first(eos),rest(eos),F,eol) = trm(F,eoa);
scfinalize(first(eos),rest(eos),null,Stck) = sccollrls(eol,Stck);
sccollrls(Rs,lst(trm(str('r',str('l',eos)),arg(L,arg(R,eoa))),Stck))
= sccollrls(trm(str('r',str('l',eos)),
arg(L,arg(R,arg(Rs,eoa)))),Stck);
sccollrls(V,eol) = V;
scsym, scspec, scdec and schx
Function scsym parses an id and returns a symbol (string) or a variable.
Function scspec parses a data value. Unlike C, Tram doesn’t need the 32-bit version of data, so all data values are represented as strings.
Since Tram doesn’t have character classes, auxiliary functions scdec and schx scan decimal and hexadecimal numbers.
| |